
Episode 04 : L'I.A.
Episode 04 : L'Intelligence Artificielle Générative
L'Intelligence
Les représentations stéréotypées des I.A.
Les robots humanoïdes (comme C-3PO dans Star Wars, Wall-E, ou Ava dans Ex Machina) dominent les représentations de l’I.A. dans la culture populaire. Ces personnages sont souvent dotés de traits humains (voix, visage, émotions), ce qui les rend plus accessibles et captivants pour le public. Les enfants, en particulier, retiennent ces images marquantes.
Des séries comme Les Jetsons ou des jeux comme Detroit: Become Human montrent des robots qui interagissent comme des humains. Ces œuvres simplifient souvent le fonctionnement de l’I.A. pour des raisons narratives en la réduisant à des réponses binaires ou à des comportements stéréotypés. Les enfants, surtout avant l’adolescence, pensent de manière concrète. Une I.A. abstraite (comme un algorithme ou un programme) est difficile à visualiser. Un robot, en revanche, est un objet physique qu’ils peuvent imaginer : il a une forme, une voix, et peut "parler". Cela répond à leur besoin de donner une forme à ce qui est invisible. L’I.A. réelle fonctionne avec des probabilités, des modèles statistiques et des données massives. Un robot qui répond est plus facile à appréhender qu’un réseau de neurones !
L'intelligence, en fait, c'est quoi ?
Il n'y a pas de réponse définitive sur ce qu'est l'intelligence. On pourrait tenter de définir l’intelligence humaine par la capacité de notre cerveau à comprendre, apprendre et s’adapter à des situations nouvelles. Elle repose sur des compétences comme la logique (résoudre des problèmes), la créativité (imaginer, inventer), et les émotions (comprendre les autres et soi-même).Grâce à la mémoire et au langage, nous partageons des idées, transmettons des savoirs et créons des cultures. Elle semble aussi liée à notre curiosité : poser des questions, explorer et donner du sens au monde et elle évolue toute la vie, en fonction de nos expériences, de notre éducation et de nos interactions avec les autres. Pendant des siècles, on a cru que l’intelligence était l’apanage exclusif des humains. Elle était inimaginable chez les animaux, et encore moins du côté des machines ! Pourtant, cette idée est devenue un fantasme puissant pour l’humanité : et si l’on parvenait à créer une machine capable de manifester des signes d’intelligence ?
Et pourtant....
Il est désormais établi que l’intelligence est bien présente chez les animaux. On n’est pas face à une distinction essentielle, mais plutôt à un gradient. Cela signifie que nous ne serions pas différents des animaux par « nature », comme on sépare actuellement le vivant organique du non-vivant minéral. Il semble que la frontière ne soit pas si nette : nous serions plutôt du côté du gradient, d’un curseur, avec des manifestations de l’intelligence qui s’échelonnent par ordre croissant — un peu, puis beaucoup, puis énormément, puis... encore plus ! L’intelligence se déploie donc sur un spectre continu, bien plus que sur des catégories figées.
Et si des animaux en sont capables, ne serait-ce qu'un peu...
Est-ce que des machines pourraient aussi manifester des compétences liées à l'intelligence ?
Pour tenter de répondre à cette question, je vais faire un pas de côté, et je vais vous présenter BOB !En 2017, OpenAI commence à entraîner des réseaux de neurones pour leur faire prédire les mots suivants. En 2022, OpenAI lance ChatGPT, après l’avoir entraîné avec des données issues de forums, de Wikipédia et de nombreuses autres sources disponibles sur Internet. Pour la première fois dans l’histoire de l’humanité, une machine répond à des requêtes comme le ferait un humain. Attention, cette machine ne dit pas forcément la vérité, mais génère des réponses probables en fonction du contexte. En 2024, ChatGPT-4 parvient à réussir l’examen du barreau de New York, ce qui lui permettrait théoriquement d’exercer en tant qu’avocat. En revanche, il échoue de peu à obtenir son diplôme de médecin. Le saut qualitatif est si impressionnant que certains « cols blancs » commencent à se sentir menacés dans leur emploi, comme les journalistes, les professeurs, les avocats, les comptables, voire les ingénieurs. En 2025, DeepSeek-R1 commence à développer des compétences de raisonnement mathématique très poussées... On en rêvait depuis un petit moment ! On pourrait faire remonter cela au début de l'automatisation, il y a environ 900 ans, lorsqu'Ismail al-Jazari, un érudit musulman, a inventé les premiers automates, horloges hydrauliques et autres appareils mécaniques.
Il semblerait donc qu'un réseau de neurones arrive à raisonner, mais, en vrai, c'est quoi un réseau de neurones ? Comment est-il possible qu'une machine, inerte, arrive à "penser" ?
Alors, on va tenter un truc ! On va essayer de comprendre quelque chose qui a été fabriqué par des matheux, pour des matheux, avec des maths.... SANS MATHS !
Les réseaux de neurones
Pour commencer, on va s'attaquer au problème suivant : nous sommes une banque. On reçoit des milliers de chèques tous les jours et on passe un temps fou à lire les chiffres qui sont incrits sur les chèques ! Est-ce qu'on pourrait pas essayer de trouver une machine qui les lise à notre place ? C'est un travail très répétitif et très ennuyeux pour les humains ! Cela ne doit pas être bien compliqué : les chèques sont toujours composés de la même façon.
Voici un chèque de banque

L'avantage, sur un chèque, on écrit tous les chiffres au même endroit :

On n'a pas besoin de reconnaitre le chèque en entier, seulement ce qui se trouve juste ici.
Le problème, c’est que l’on n’écrit jamais exactement les chiffres de la même façon ! Ils se ressemblent, mais ne sont jamais strictement identiques.

Tout comme Sila, qui se donne pourtant beaucoup de mal pour apprendre à écrire, nous ne traçons jamais les chiffres de la même manière. Cela demande même un travail considérable à notre cerveau, et les adapter à l’informatique se révèle particulièrement difficile. Cela peut sembler surprenant, mais les mathématiciens ont buté sur ce problème pendant des décennies ! Pourquoi ?
Les I.A. basées sur des systèmes experts n’y arrivent pas, car elles ne parviennet pas à gérer les variations.
Les I.A. expertes reposent sur des systèmes stables et immuables : les villes restent toujours à la même distance les unes des autres, et les pages web conservent la même URL. On peut facilement les classer dans un tableau, même s’il contient des millions d’entrées. Elles y sont toujours à la même place !
Des I.A. comme celles de Google, expertes pour recenser tous les sites web du monde, se heurtent au problème de la variation.
Lorsqu’on aborde ce problème de manière traditionnelle en informatique, on commence par traiter une zone très réduite : un carré de 28 par 28 pixels, par exemple. Bien que cette zone soit minuscule, elle est suffisante pour y inscrire des chiffres allant de 0 à 9.
Même dans un tout petit espace, les chiffres ne sont jamais écrits à la même place ! Ils peuvent être partout ! En haut, en bas, au centre, et n'ont pas la même taille ! Et même dans une toute petite image, les possibilités sont gigantesques !
Juste un petit calcul : Une image de 28 pixels par 28 pixels, c'est minuscule ! Ca ressemble à cela !

C'est minuscule, et pourtant cela fait 28x28 = 784 pixels, et le nombre de configurations possibles de cet espace de 784 pixels, en noir et blanc, c'est 256 x 256 x 256 x 256 x 256 x 256 x 256 ........ x 256, 784 fois de suite ! Bon, je l'avoue, j'ai un peu la flemme de taper 784 fois 256x256, du coup je demande à une I.A. de le faire pour moi. Je rédige le prompt suivant: Est-ce que tu saurais faire le calcul suivant : 256 multiplié par 256, 784 fois de suite. N'hésite pas à poser le calcul, étape par étape ! La réponse du chatbot est la suivante : Pour calculer 256 multiplié par lui-même 784 fois, il s'agit d'une opération extrêmement complexe à réaliser manuellement en raison de la taille astronomique du résultat. Voici pourquoi : Ordre de grandeur du résultat : Quand on le fait deux fois : 256 x 256 = 65 536 Quand on le fait trois fois : 256 x 256 x 256 = 16 777 216 Quand on le fait cinq fois : 256 X 256 x 256 x 256 x256 = 1 099 511 627 776 Quand on le fait dix fois : 256 X 256 x 256 x 256 x 256 x 256 X 256 x 256 x 256 x256 = A peu près 1 000 000 000 000 000 000 000 000, un 1 suivi de 24 zéros ! Quand on le fait 784 fois: la taille du nombre dépasse largement la capacité de calcul manuel ou même celle des calculatrices standards. Comment le calculer avec précision ? Je peux utiliser mon interpréteur Python pour obtenir le résultat exact. Veux-tu que je le fasse ? Si oui, je te donnerai le nombre exact (ou ses premiers et derniers chiffres, car il sera très long). En langage chatbot, cela est peu prêt l'équivalent de : "NON MAIS CA VA PAS ?" Du coup, on a cru que cela n'était tout simplement pas possible ! C'est même une des raisons qui ont provoqué le deuxième hiver de l'i.a. dans les années 80. Jusqu'au jour où ....
Imitation Game, Morten Tyldum, 2014
Allan Turing, père de l'I.A. s'était déja heurté au problème d'un trop grand nombre d'inconnues... dans les années 1940 !
Au tout début des années 1990, Yann Le Cun va montrer la chose suivante : si on pioche des images parmi les milliards de milliards de possibilités, ce que l'on va trouver, ce sont presque toujours des images de ce genre là :

Or, nous, on cherche des configurations de ce genre là :
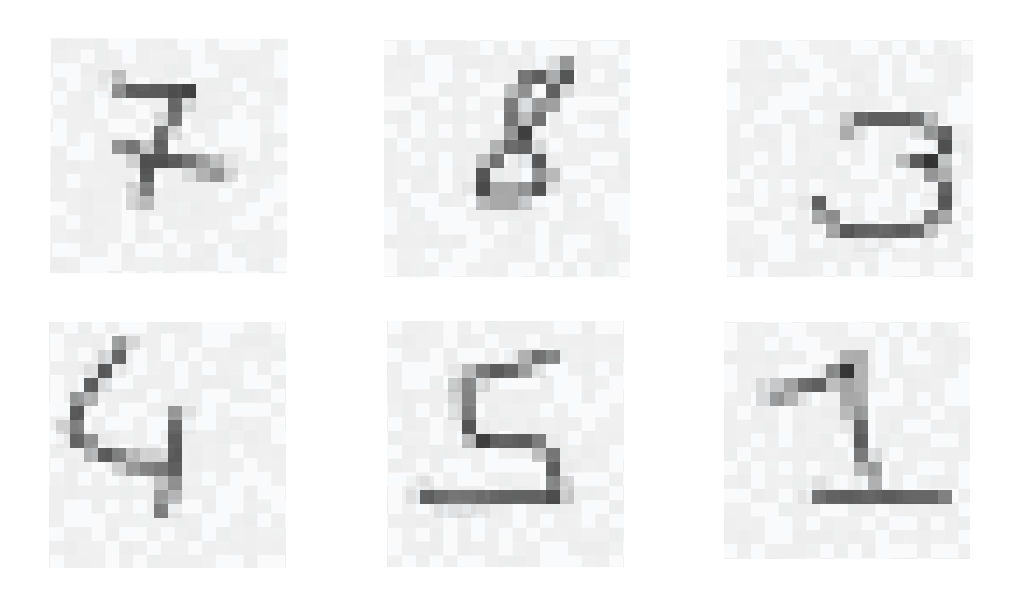
Et bien, ce type de configurations est extrêmement improbable, de l’ordre d’1 chance sur des milliards de milliards. Le défi était de pouvoir débusquer ces formes particulièrement rares.
L’idée géniale a été de se dire : au lieu de chercher à identifier toutes les configurations extrêmement rares, pourquoi ne pas entraîner un réseau de neurones à les reconnaître avec une certitude suffisante ? Ainsi, il pourrait réaliser une prédiction du type : « Nous pensons qu’il s’agit d’un 4, avec 90 % de certitude. »
Les chiffres manuscrits présentent de nombreuses variations. L’enjeu est d’arriver à les identifier tout en les distinguant les uns des autres.
L’idée de Yann LeCun est de dire que ce n’est pas un problème d’algèbre, mais de géométrie.
Pour y parvenir, il faut créer un réseau de neurones qui va rechercher des types de formes spécifiques et réduire le nombre de possibilités à chaque étape : au début, il y en a 784, et à la fin, il n’en reste plus que 10 ! C'est cette structure spécifique qu'on appelle un réseau de neurones !
L’astuce consiste à repérer des structures spécifiques dans l’ensemble des 784 pixels choisis. Il s’agit de déterminer si ces pixels s’ordonnent en des formes géométriques spécifiques, telles que des lignes, des cercles, des courbes… Bref, des formes géométriques récurrentes qui différencient les chiffres les uns des autres.
L’idée est d’utiliser tous les pixels comme entrées dans un tableau, soit 784 entrées à gauche, et de n’avoir en sortie, sur la dernière colonne, que des valeurs numériques. On va ainsi passer d'une image pour la synthétiser progressivement en un nombre unique. Chaque valeur indiquera le pourcentage de probabilité que le chiffre corresponde à l’une des valeurs suivantes : 0, 1, 2, 3, 4, 5, 6, 7, 8 ou 9
On va ainsi construire un réseau neuronnal en 4 couches, ou 4 étapes, où chaque étape va essayer de déterminer le motif du chiffre : Etape 01 : les points Etape 02 : les lignes ou les courbes Etape 03 : les formes Etape 04 : les motifs
La première couche : identifier les points
À partir d’une image de 28 pixels par 28 pixels, chaque pixel sera transformé en un point blanc ou noir. Si un pixel est proche de 0, il est considéré comme noir : on lui attribue la valeur 0, ce qui signifie qu’il est inactif et fait partie du fond de l’image. S’il est proche de 255, il est blanc et devient un pixel important, car il doit être impliqué dans un ensemble plus grand, une forme spécifique qui reste à identifier. On lui attribue alors la valeur 1
La quatrième couche : identifier les chiffres
Dans la dernière couche du réseau, celui-ci sélectionne le chiffre que la machine a identifié comme ayant la plus forte probabilité d’être présent sur l’image. En réalité, le réseau attribue une probabilité à chaque réponse possible, mais c’est celle qui a reçu la probabilité la plus élevée (la plus proche de 1) qui est retenue. Par exemple, une probabilité de 0,005 est très faible, tandis qu’une probabilité de 0,999 indique une quasi-certitude.
La troisième couche : identifier les motif
Chaque chiffre est composé d’un assemblage de motifs identifiables qui le distinguent des autres chiffres. Un 9, par exemple, est formé d’une boucle haute et d’une ligne verticale. Un 6, quant à lui, se compose d’une boucle basse et d’une ligne verticale. En combinant les motifs que le réseau a identifiés, celui-ci cherche à déterminer quel chiffre contient tous les motifs détectés. Pour ce faire, il attribue une probabilité en fonction des formes qu’il a reconnues.
La deuxième couche : identifier des lignes
À partir des points formés par les pixels, le réseau va déterminer la présence de petites lignes ainsi que leur position sur l’image. Ces petites lignes sont formées par des points qui se touchent. Le réseau va donc tenter d’identifier l’ensemble des points de contact en fragmentant l’image en petites zones. Cela lui permettra de repérer quelles lignes forment des motifs dans la couche suivante.
Bilan
Le réseau parvient ainsi à reperer des chiffres en passant des pixels aux points, puis des points aux lignes, puis des lignes aux formes, puis de formes aux chiffres.
C'est bien joli, mais comment un réseau fait-il pour apprendre ?
Pour répondre à cette question, je vais faire un petit pas de côté et passer par la physique !
Yann LeCun va ainsi partir des travaux de Hopfield pour construire un réseau de neurones capable de mémoriser des motifs de chiffres allant de 0 à 9 et de réaliser des prédictions pour chacune des images qu’on lui présente, afin de déterminer avec la plus grande probabilité possible s’il s’agit d’un 0 ou d’un 7.
Ce réseau particulier comporte 13 002 paramètres, qu’il faudra ajuster grâce à des fonctions mathématiques appelées poids et biais. Ces paramètres sont souvent surnommés "boutons" (ou hyperparamètres dans un contexte plus technique). Ils permettent au réseau, par un processus de va-et-vient de type "essai-erreur" d’ajuster progressivement les connexions neuronales jusqu’à obtenir un taux de prédiction satisfaisant.
Ici, on observe le réseau de neurones s’entraîner et progresser de manière autonome. Pour cela, on l’entraîne sur des milliers d’images manuscrites en lui fournissant la bonne réponse. Si le modèle a trouvé la bonne réponse, tout va bien. S’il s’est trompé, il va ajuster ses paramètres pour se recalibrer et améliorer ses réglages.

On utilise alors la technique des petits pas : le réseau va ajuster progressivement ses paramètres pour identifier les bonnes configurations. Ces « bonnes configurations » sont difficiles à visualiser, car, dans cet exemple, elles appartiennent à un espace de 13 000 dimensions — une réalité qui n’existe que dans la mémoire d’un ordinateur.
Pour s’en faire une petite idée, prenons une analogie : lorsque l’on n’arrive pas à reconnaître un mot parce que son orthographe est trop altérée, on peut essayer de le prononcer à voix haute. Le son, cette autre dimension, est souvent à l’origine de la reconnaissance du mot. Celui que l’on ne parvenait pas à identifier visuellement devient soudain évident une fois articulé. Dans notre cerveau, deux dimensions — la vue et l’ouïe — sont reliées et activent la même zone de reconnaissance dans notre propre réseau neuronal !
Dans notre cerveau, on peut ressentir le lien entre la vue et l’ouïe. Mais dans un réseau de neurones, les 13 000 dimensions sont invisibles : on ne peut pas "voir" ou "entendre" comment elles interagissent. On observe seulement le résultat final (la prédiction), sans comprendre précisément quel paramètre a fait basculer la décision.
Ici, on rencontre une limite : le réseau ne parvient pas à identifier correctement le chiffre donné en entrée. On parle souvent de « boîte noire », car, dans ce cas, il est très difficile de savoir précisément pourquoi le réseau a échoué. On peut en deviner les raisons de manière intuitive, mais on ignore quel paramètre spécifique est à l’origine de l’erreur.
On pourrait croire que ce problème de boîte noire serait fatal aux IA génératives, et pourtant, il se trouve que cela va se révéler être leur plus grande force. Certes, elles peuvent se tromper, mais c’est justement cette capacité à inventer qui va faire que les IA vont réussir à devenir créatives !
La reconnaissance d'image : Le deep learning
Ce sont des réseaux neuronaux qui ne comportent pas une, ni deux, mais des centaines de couches intermédiaires.
En 2012, l’algorithme AlexNet, développé par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton, a marqué un tournant dans l’histoire de l’intelligence artificielle en remportant le concours ImageNet ILSVRC avec un taux d’erreur de 15,3 %, soit une amélioration spectaculaire par rapport aux 26,2 % des méthodes classiques de l’époque. Ce réseau de neurones convolutif (CNN) profond, entraîné sur 1,2 million d’images, a prouvé que les modèles pouvaient apprendre automatiquement des caractéristiques visuelles complexes, sans ingénierie manuelle. Grâce à l’exploitation des GPU, l’équipe a réduit le temps d’entraînement de plusieurs semaines à quelques jours, rendant le deep learning pratique et opérationnel. Cette victoire a sonné le glas des approches traditionnelles et déclenché une révolution : les géants technologiques ont massivement adopté les CNN, et le deep learning est devenu la norme en vision par ordinateur, ouvrant la voie à des applications comme la reconnaissance faciale, les voitures autonomes ou le diagnostic médical.
Ici, il ne s’agit plus seulement de reconnaître des chiffres, mais des catégories entières d’images : chats, chiens, voitures, motos, maisons… Le principe reste le même, mais à une échelle bien plus grande. Pour y parvenir, les réseaux de neurones doivent comporter des centaines de millions de paramètres, capables de capturer la complexité et la diversité de ces objets.
Les raisons du succès des réseaux de Deep Learning reposent sur trois paramètres principaux : La configuration de réseaux composés de centaines de couches intermédiaires ; L’augmentation de la puissance de calcul, notamment grâce à l’utilisation de GPU, des cartes graphiques fabriquées par Nvidia ; L’accès à de grandes bases de données pour entraîner les modèles, fournies notamment par Internet et les réseaux sociaux.
2016 : ALPHA GO Première I.A. reconnue comme créative
AlphaGo, AlphaGo (2017), réalisé et écrit par Greg Kohs, est un excellent documentaire qui raconte un choc célèbre entre l’homme et la machine ! Imagine : 2016, un robot surdoué, AlphaGo, développé par les génies de DeepMind, défie Lee Sedol, 7 fois champion du monde du jeu de go. Un duel épique qui s’est joué à Séoul, et qui a tout changé ! Ce documentaire te plonge dans cet affrontement : l’intelligence humaine VS l’intelligence artificielle. Tu peux voir l’intégralité de ce documentaire en téléchargeant la vidéo ci-dessous : fais un clic droit sur le lien, puis sélectionne l’option « Enregistrer la cible du lien sous » (ou « Enregistrer le lien sous » selon ton navigateur).
En 2016, un événement historique secoue le monde du jeu de Go, un jeu de stratégie millénaire bien plus complexe que les échecs. AlphaGo, un programme d’intelligence artificielle développé par la société DeepMind (filiale de Google), affronte Lee Sedol, l’un des meilleurs joueurs humains de Go au monde. Ce match oppose l’intuition humaine à la puissance de calcul d’une machine. Le Go, avec ses règles simples mais ses combinaisons quasi infinies, était considéré comme un défi insurmontable pour l’IA. Pourtant, AlphaGo a appris à jouer en analysant des millions de parties et en s’entraînant contre lui-même grâce à une technique appelée apprentissage par renforcement. Contrairement aux programmes classiques, AlphaGo ne se contente pas de calculer toutes les possibilités : il "comprend" les stratégies et invente des coups créatifs. Le match se déroule sur cinq parties. Dès la première, AlphaGo surprend le monde en battant Lee Sedol. Le joueur coréen, confiant, remporte la quatrième partie grâce à un coup de génie, mais perd finalement le match 4-1. Ce qui marque les esprits, c’est la manière dont AlphaGo joue : certains de ses coups, comme le coup 37 de la deuxième partie, sont si innovants qu’ils bouleversent la façon dont les humains envisagent le jeu. Ce coup semblait bizarre, comme si AlphaGo faisait une erreur… mais en réalité, c’était un coup de génie ! Il a montré que la machine pouvait inventer des stratégies que les humains n’avaient jamais imaginées. Pourquoi c’est révolutionnaire ? AlphaGo a appris tout seul en analysant des millions de parties. Il a fait évoluer la manière de jouer, comme un artiste qui invente un nouveau style.
Les humains ont réalisé que les machines pouvaient être créatives, pas juste logiques.
Depuis, les joueurs de go copient ce coup ! C’est comme si un robot avait appris aux humains une nouvelle façon de jouer… et de penser ! Cette victoire symbolise une avancée majeure pour l’IA : elle prouve qu’une machine peut maîtriser l’intuition et la créativité, des qualités qu’on croyait réservées aux humains. Aujourd’hui, AlphaGo a inspiré des avancées dans d’autres domaines, comme la médecine ou la recherche scientifique.
Cette manière d’apprendre, pour une IA, en jouant des millions de parties contre elle-même, s’appelle l’apprentissage automatique (machine learning en anglais).
Le machine Learning : Les réseaux de convolution
L’apprentissage automatique (machine learning), c’est comme si une IA était un super joueur de jeu vidéo. Au lieu de lui donner un manuel avec toutes les règles, on la laisse jouer des milliers de parties toute seule. À force de gagner, perdre et recommencer, elle comprend les meilleures stratégies sans qu’on ait besoin de tout lui expliquer. C’est comme ça qu’AlphaGo a battu les champions de go : en s’entraînant contre elle-même jusqu’à devenir imbattable ! Une variante de cette technique est appliquée à la reconnaissance d’images. On appelle ce type de réseau de neurones un réseau de convolution. Un réseau de convolution, c’est comme si les paramètres du réseau agissaient comme une équipe de super-détectives pour analyser une image. Imagine que tu regardes une photo de chat : Le premier détective repère les bords (les contours des oreilles, des moustaches…). Le deuxième identifie les formes (un triangle pour les oreilles, des ovales pour les yeux…). Le troisième assemble tout ça : « Bords + formes = un chat ! » 🐱. Un réseau de convolution, c’est exactement ça, mais en version numérique : Il scanne l’image par petites zones. Il apprend à reconnaître des motifs (un œil, une roue, un visage…) grâce à des millions d’exemples. À la fin, il peut dire : « Ça, c’est un chat ! » ou « Ça, c’est une pizza ! »
Différences entre prédiction et génération
Un réseau de neurones en mode prédiction a pour but d’analyser une image existante pour en extraire des informations. Par exemple, un modèle comme ResNet ou EfficientNet va prendre en entrée une photo et classifier son contenu : "C’est un chat à 95 %", "C’est une voiture rouge", ou encore "Cette tumeur est maligne". Ici, le réseau ne crée rien ; il interprète ce qui est déjà présent en s’appuyant sur des motifs appris pendant son entraînement (bords, textures, formes). La prédiction repose sur des données labellisées et c’est un processus déterministe : pour une même image, le résultat sera toujours le même. À l’inverse, la génération d’images consiste à créer de nouvelles images à partir de zéro (ou presque). Des modèles comme les GANs (Generative Adversarial Networks) ne partent pas d’une image existante, mais d’une description textuelle. Leur objectif n’est pas de classifier, mais de produire des données réalistes en apprenant la distribution statistique des images d’entraînement. Par exemple, si on demande à un GAN de générer "un coucher de soleil sur une montagne", il va inventer une image plausible, pixel par pixel, en combinant ce qu’il a appris sur les couleurs, les formes et les textures. Cliquer sur le lien ci dessous pour accéder au site "This person does not exist" et voir travailler cette I.A. en direct. https://this-person-does-not-exist.com/en
Les réseaux supervisés et les réseaux non supervisés
Réseau supervisé : comme un prof qui donne les réponses Imagine que tu apprends à reconnaître des chats et des chiens 🐱🐶 : On te montre 1000 photos en te disant : « Ça, c’est un chat. Ça, c’est un chien. » À force, tu apprends les différences (oreilles pointues, queue touffue, etc.). Résultat : quand on te montre une nouvelle photo, tu peux dire « Chat ! » ou « Chien ! » sans hésiter. Exemple réel : Quand ton téléphone reconnaît ton visage pour se déverrouiller. Quand Netflix te propose des films parce que tu as aimé d’autres films similaires. Réseau non supervisé : comme un détective qui découvre tout seul Maintenant, imagine qu’on te donne 1000 photos de chats et de chiens… mais sans te dire lequel est lequel 🕵️♂️. Toi, tu dois trouver des ressemblances tout seul : « Ces animaux ont des moustaches → groupe 1. Ceux-là aboient → groupe 2. » Tu inventes des catégories sans qu’on te guide. Exemple réel : Quand un site de shopping te propose « Les clients qui ont acheté ce pull ont aussi aimé ce jean » (sans savoir pourquoi, juste parce que les données se ressemblent). Quand Spotify crée une playlist « Découverte » avec des musiques qui se ressemblent, mais sans savoir si tu vas aimer. La différence en une phrase : Supervisé = On donne les réponses à l’IA (comme un cours avec un prof). Non supervisé = L’IA cherche des patterns toute seule (comme un explorateur sans carte).
Les I.A. génératives
L’idée de base : Partir du bruit pour créer une image
Le réseau de neurone va se comporter de deux manières différentes: Un destructeur : Il ajoute du bruit à une image réelle jusqu’à ce qu’elle devienne méconnaissable (c’est l’entraînement de l’IA). Un reconstructeur : L’IA apprend à faire l’inverse : partir du bruit pour "halluciner" l’image. Partir d’une image pleine de bruit, c’est un peu comme donner à l’IA une toile vierge et infinie pour créer quelque chose de totalement nouveau. Imagine que tu veux inventer un personnage de jeu vidéo : si tu commences toujours avec le même croquis, tes créations finiront par se ressembler. Le bruit aléatoire, c’est comme lancer des dés avant de dessiner. Ça permet à l’IA d’explorer toutes les possibilités sans être bloquée par des idées préétablies. Sans ce hasard, les images générées seraient toutes similaires, comme des photocopies avec de petites variations.
Le bruit, c’est aussi ce qui rend chaque création unique et imprévisible. Par exemple, si tu demandes « un oiseau futuriste », l’IA pourrait te proposer un oiseau avec des ailes métalliques, un autre avec des plumes lumineuses, ou même un mélange des deux. Sans cette part d’aléatoire, toutes les images ressembleraient à une version légèrement modifiée d’un même modèle de base. Techniquement, c’est une façon pour l’IA d’éviter de se coincer dans des solutions trop simples ou répétitives. En partant du chaos, elle apprend à affiner progressivement les détails, comme un artiste qui part d’une esquisse floue pour aboutir à une œuvre précise. Enfin, c’est ce qui permet à l’IA de capturer la diversité du monde réel, où rien n’est parfaitement identique.
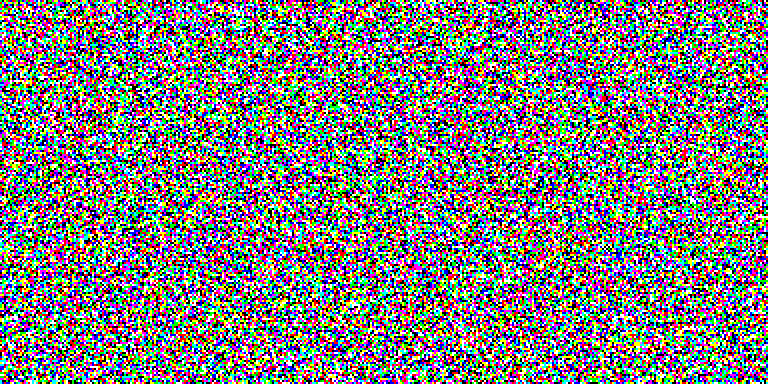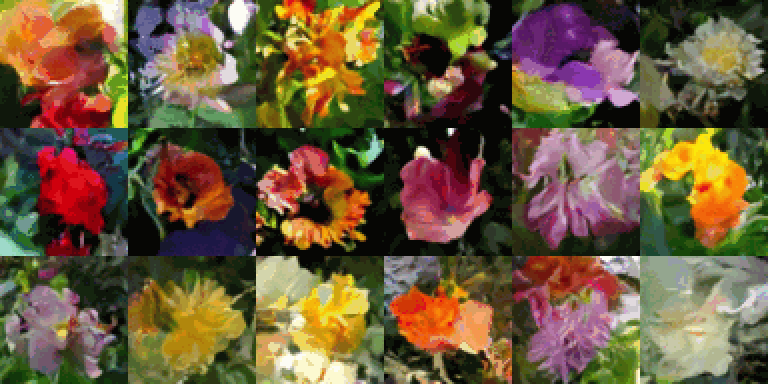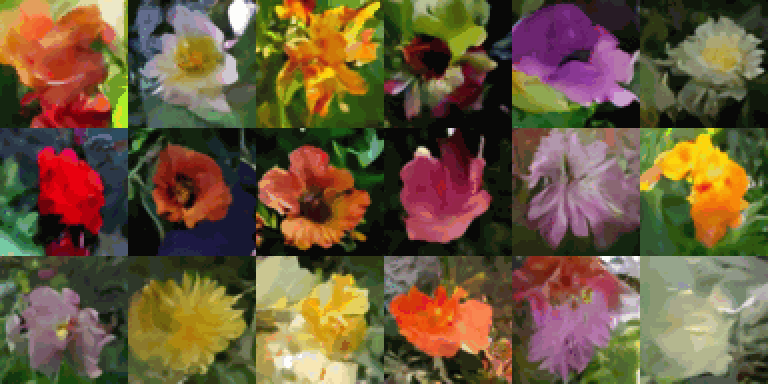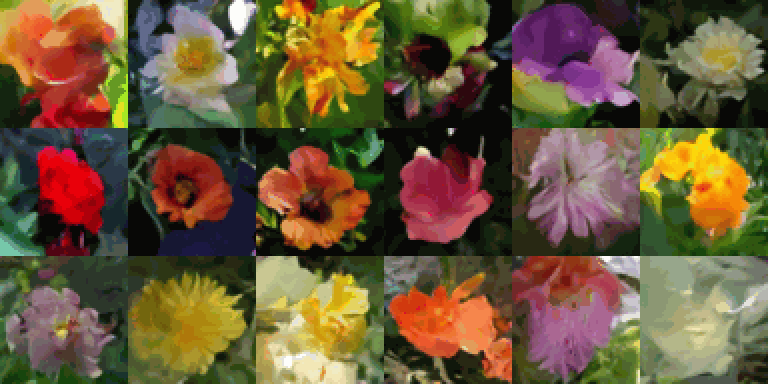
L’aléatoire, c’est le cœur battant de la créativité des IA, mais aussi une source d’inspiration intemporelle pour les artistes. Depuis toujours, les humains ont exploité le hasard pour stimuler leur imagination : que ce soit en observant les formes étranges des nuages, comme le faisait Léonard de Vinci, en décryptant les motifs des fissures sur les murs, ou en s’inspirant des contours des champignons ou des moisissures. Cette technique, appelée paréidolie, consiste à voir des images familières là où il n’y en a pas vraiment — un jeu entre l’esprit et le chaos, où le cerveau transforme l’abstrait en quelque chose de reconnaissable.

Les IA modernes fonctionnent un peu de la même manière : elles partent d’un désordre total, comme une toile de bruit aléatoire, puis, étape par étape, elles sculptent ce chaos pour en faire une image cohérente et unique. Ce mélange de hasard initial et de méthode progressive permet de créer, à chaque fois, des œuvres nouvelles et inattendues, comme si l’IA jouait à deviner des formes dans les nuages. Une danse entre le désordre et l’ordre, où chaque création devient une surprise !

Le plongement
Le plongement (ou embedding), c’est comme un code qui permet à un réseau de neurones de comprendre et créer des images à partir de mots. Imagine que chaque image ou mot est transformé en une liste de nombres qui capture son essence : un chat roux, un ciel étoilé, ou un style "à la Van Gogh". Ces nombres sont calculés pour que des choses similaires (comme deux chats) aient des codes proches, et des choses différentes (un chat et une voiture) aient des codes éloignés. Quand tu demandes à un outil comme DALL·E ou MidJourney de générer "un robot qui fait du skate", voici ce qui se passe : Ton texte est converti en un code numérique (le plongement). Le réseau compare ce code à des millions d’autres qu’il connaît (des robots, des skates, etc.). Il mélange ces informations pour inventer une nouvelle image qui correspond à ta demande. Grâce aux plongements, les réseaux peuvent aussi : Transformer une photo (ex. : te vieillir ou te donner des cheveux bleus). Fusionner des styles (ex. : un paysage dessiné comme un tableau de Picasso). Créer des images réalistes en quelques secondes, juste avec une phrase. En résumé, le plongement, c’est la recette qui permet aux IA de comprendre tes mots et de les transformer en images, comme si tu donnais une idée à un artiste qui la dessine instantanément !
Un coût environnemental élevé !
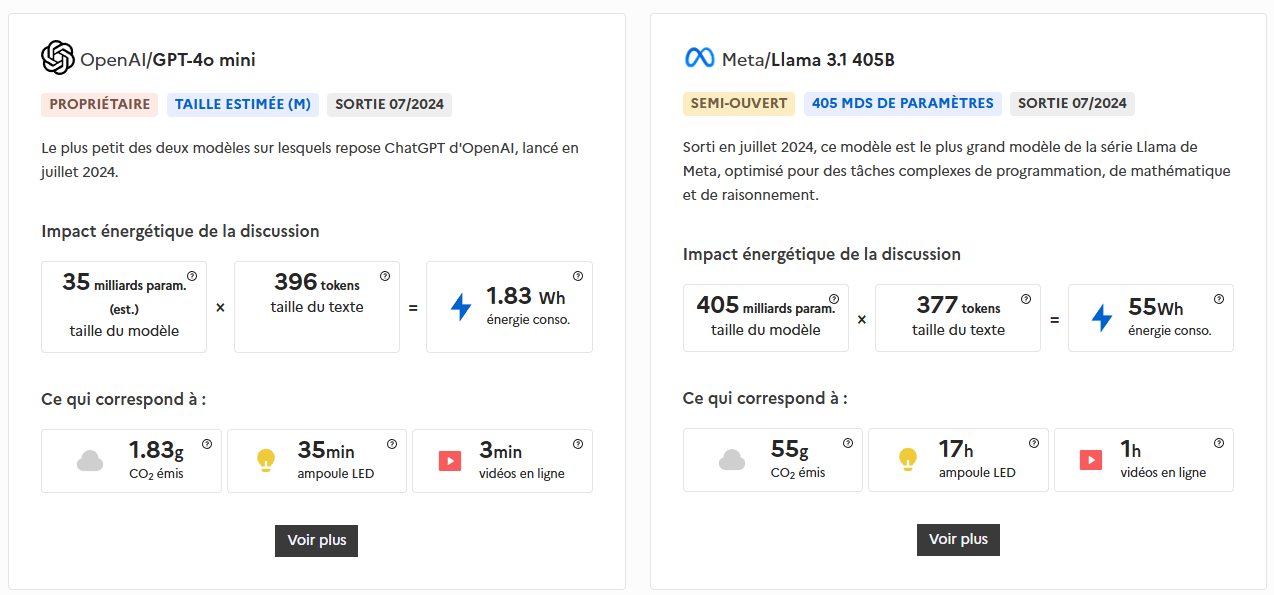
Les intelligences artificielles, pour fonctionner, mobilisent d’importantes ressources naturelles, consomment une quantité significative d’énergie et génèrent une pollution non négligeable. Par exemple, une simple requête d’environ 400 tokens sur un modèle comme ChatGPT ou GPT-4o mini (comptant 35 milliards de paramètres) nécessite environ 2 wattheures (Wh) d’électricité, soit l’équivalent de 35 minutes d’éclairage avec une ampoule LED ou de 3 minutes de streaming vidéo. Pour rappel, un wattheure correspond à l’énergie consommée par un système d’une puissance d’1 watt pendant une heure.
Cette consommation dépasse largement celle d’une recherche Google classique, estimée à 0,3 Wh, soit plus de six fois moins. Les modèles plus gourmands, comme Meta / Llama 3.1 405B (avec ses 405 milliards de paramètres), voient la consommation d’une requête similaire s’envoler à 55 Wh, ce qui équivaut à l’émission de 55 grammes de CO₂. Autre exemple frappant : la génération d’une image en haute définition par une IA consomme autant d’énergie que la recharge complète d’un smartphone.
Les centres de données, qui soutiennent notamment les activités liées à l’IA et aux cryptomonnaies, ont déjà consommé près de 460 térawattheures (TWh) d’électricité en 2022, représentant environ 2 % de la production mondiale. Selon de nombreux experts, cette part pourrait bien doubler en 2026, soulignant l’urgence de repenser l’impact environnemental de ces technologies.
Pour en savoir plus, tu peux consulter les sources que j’ai utilisées pour rédiger ce paragraphe en cliquant sur le lien ci-dessous. https://drane-versailles.region-academique-idf.fr/spip.php?article1167
Une compétition géopolitique intense
L’intelligence artificielle (IA) est devenue un enjeu géopolitique majeur, cristallisant une rivalité technologique sans précédent entre la Chine et les États-Unis. Cette compétition s’explique par trois facteurs clés : la suprématie économique, la sécurité nationale et l’influence mondiale. 1. Suprématie économique L’IA est un moteur de croissance et d’innovation. Les États-Unis, avec des géants comme Google, Microsoft et Nvidia, dominent les infrastructures (cloud, puces électroniques) et les applications (algorithmes, logiciels). La Chine, via des entreprises comme Alibaba, Tencent ou Huawei, mise sur une adoption massive de l’IA dans l’industrie, la santé et les services publics. Les deux pays investissent des milliards pour contrôler les chaînes de valeur technologiques, car l’IA redéfinit la productivité et la compétitivité des économies. 2. Sécurité nationale et défense L’IA est un multiplicateur de puissance militaire. Les États-Unis développent des systèmes autonomes (drones, cyberdéfense) pour maintenir leur avance stratégique, tandis que la Chine intègre l’IA dans sa doctrine de « guerre intelligente », combinant surveillance de masse (reconnaissance faciale) et armements autonomes. La maîtrise de l’IA permet de décrypter des données adverses, d’anticiper les conflits et de neutraliser des menaces, rendant cette technologie indispensable à la souveraineté. 3. Influence mondiale et normes technologiques Le leadership en IA permet d’imposer des standards internationaux. Les États-Unis, via des alliances (comme le Chip 4 avec le Japon, la Corée du Sud et Taïwan), cherchent à limiter l’accès chinois aux technologies critiques (semi-conducteurs). La Chine, avec son initiative « Nouvelle Route de la Soie numérique », exporte ses solutions d’IA en Asie et en Afrique, promouvant un modèle alternatif de gouvernance technologique. Cette bataille des normes détermine qui façonnera l’avenir numérique. Enjeux éthiques et risques Cette course pose des défis : course aux armements autonomes, surveillance intrusive, et fractures technologiques. Les deux puissances accusent l’autre de menacer la stabilité mondiale, tout en accélérant leurs propres programmes. La rivalité sino-américaine en IA est bien plus qu’une compétition technologique : c’est un affrontement pour le pouvoir au XXIe siècle. Qui dominera l’IA contrôlera non seulement l’économie et la défense, mais aussi les règles du monde de demain.
Attention l'IA générative ne dit pas la verité, elle ne dit que des choses probables !


Ces scènes, particulièrement réalistes, ont été créées à l’aide de Midjourney, un outil disponible sur internet et reposant sur ce qu’on appelle l’intelligence artificielle (IA) générative. Fondé en 2022 par l’Américain David Holz, Midjourney est capable « de créer en quelques secondes une fausse photographie, à partir d’une simple requête d’un internaute ».
Les fake news créées par l’intelligence artificielle sont devenues un danger sérieux, surtout pour les jeunes comme vous qui passez beaucoup de temps en ligne. Imaginez : une IA peut fabriquer en quelques secondes des images, des vidéos ou des articles ultra-réalistes, mais totalement faux. Par exemple, elle peut inventer une citation d’une célébrité qui n’a jamais été prononcée, montrer une vidéo d’un événement qui n’a jamais eu lieu, ou même créer un faux profil sur les réseaux sociaux pour manipuler l’opinion. Le problème, c’est que ces contenus sont souvent impossibles à distinguer du vrai à l’œil nu. Pourquoi c’est dangereux ? Parce que ces fausses informations peuvent semer la panique, nuire à la réputation de quelqu’un, ou même influencer des élections en trompant des millions de personnes. Une rumeur lancée sur TikTok ou Instagram peut devenir virale en quelques heures, et une fois partagée, il est très difficile de rattraper la vérité. Les algorithmes des réseaux sociaux favorisent souvent les contenus choc, même s’ils sont faux, ce qui amplifie le phénomène. En tant qu’ado, vous êtes une cible privilégiée : les créateurs de fake news savent que vous êtes rapides à partager ce qui vous surprend ou vous émeut, sans toujours vérifier. Alors, comment vous protéger ? Méfiez-vous des titres sensationnalistes, vérifiez les sources avant de partager, et utilisez des outils comme les sites de fact-checking (comme Les Décodeurs ou AFP Factual). N’oubliez pas : derrière chaque contenu, demandez-vous qui l’a créé, pourquoi, et comment il a été vérifié. Votre esprit critique est votre meilleure arme.
La désinformation, ça se combat en restant informé, vigilant et responsable.
Pour finir, un petit lien vers un site de fact-checking en ligne tenu par Yann tout court, c'est rigolo et très bien fait ! Vous pouvez retrouver l'ensemble de ces vidéos en cliquant sur le lien ci-dessous. Yanntoutcourt
HugodecryptePour aller plus loin ! Une autre approche, qui explique plusieurs manières d’entraîner des machines à apprendre ! Une autre façon de raconter la même histoire, mais tout aussi passionnante, dans la vidéo suivante :
Un petit quizz pour savoir si tout est bien compris
1. Pourquoi les robots humanoïdes (comme C-3PO ou Ava) dominent-ils les représentations de l’IA dans la culture populaire ?
Parce qu’ils sont plus faciles à programmer
Parce qu’ils rendent l’IA plus accessible et captivante en lui donnant une forme humaine.
Parce que ce sont les seuls types d’IA qui existent réellement.
2. Qu’est-ce que l’intelligence, selon le cours ?
Une capacité exclusive aux humains.
Une compétence réservée aux machines.
Un gradient qui s’étend des animaux aux machines, avec des manifestations variées.
3. Quel était le défi principal pour les premières IA dans la reconnaissance des chiffres manuscrits ?
La gestion des variations dans l’écriture des chiffres.
La taille des images.
Le manque de puissance de calcul.
4. Qu’est-ce qu’un réseau de convolution (CNN) ?
Un réseau qui analyse une image en détectant des motifs (bords, formes, textures) à travers plusieurs couches.
Un réseau qui ne fonctionne qu’avec des images en noir et blanc.
Un réseau qui ne sert qu’à reconnaître des visages.
5. Quelle est la différence entre un réseau supervisé et un réseau non supervisé ?
Le supervisé est plus rapide, le non supervisé est plus précis.
Le supervisé ne fonctionne qu’avec des images, le non supervisé qu’avec du texte.
Le supervisé apprend avec des données étiquetées, le non supervisé découvre des motifs tout seul.
6. Comment les IA génératives créent-elles des images à partir de zéro ?
Elles copient des images existantes.
Elles partent d’un bruit aléatoire et le transforment progressivement en une image cohérente.
Elles utilisent uniquement des photos prises par des humains.